![[Spring Data JPA] saveAll은 만능일까?](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbdLrfa%2FbtrZkboHLvF%2FAAAAAAAAAAAAAAAAAAAAAF6JJOZdBxGbXEhvGllnHrE8eUOHmnB7fC7G-nhPsGpm%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DxQfZRQ86e%252BUCKIkXd4rTPIJGeb4%253D)
개발 환경
필자의 개발 환경에 맞추어 포스팅되었으니 참고 바랍니다.
- Java / Gradle
- Spring Boot 2.7.8
- Spring Data JPA
- MySQL 8.0.24
개요
이번에 간단한 팀 프로젝트를 진행하면서 Spring Data JPA를 사용했습니다.
평소에 자주 애용하던 KREAM의 백엔드 서버를 분석하고 구현하는 프로젝트였는데, 필자는 이 프로젝트에서 스타일 파트를 맡았습니다.
스타일은 일종의 인스타그램과 매우 비슷했는데, 특이한 점으로는 KREAM에서 거래 중인 상품을 태그 할 수 있다는 점이었습니다.
해당 도메인의 피드 등록 기능을 개발하던 중 피드에 들어가는 해쉬태그(#)나 상품들을 별도 테이블로 분리해서 관리할 필요가 있었습니다. 테이블이 분리되었기 때문에 하나의 피드가 등록될 때면 여러 개의 해쉬태그, 피드 상품들이 테이블에 저장되는 구조가 되었습니다.
컬렉션으로 추출된 해쉬태그, 상품 리스트들이 JPA Repository에서 기본적으로 제공하는 saveAll 메서드를 통해 잘 들어가는 것을 확인했습니다.
그런데 과연 문제가 없을까요?
여러 건의 데이터를 넣을 때에는?
Spring Data JPA를 사용하여 개발할 때 우리는 다건 삽입에 대해 크게 고민할 필요가 없습니다.
JPA Repository를 상속받게 되면 SimpleJPARepository 구현체를 만들어주기 때문인데요.
해당 구현체의 삽입, 수정 관련 메서드는 다음과 같습니다.
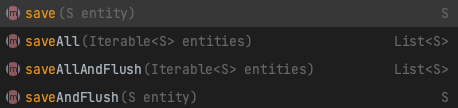
영속성 관련 이야기만 해도 너무 길어지니 생략하고
JPA는 save(AndFlush), saveAll(AndFlush)를 통해서 하나의 엔티티를 데이터베이스에 삽입, 수정하거나 여러 엔티티를 한 번에 삽입, 수정할 수 있도록 기본적인 메서드를 제공합니다.
내부 로직을 살펴보면 save와 saveAll은 다음과 같습니다.


서비스 로직에서 Loop를 돌며 save를 하거나 saveAll를 통해 다건의 데이터를 삽입할 수 있겠죠.
(실제로는 트랜잭션과 관련하여 save의 비용이 더 높습니다. save vs. saveAll 키워드로 찾아보길 권장합니다.)
saveAll의 문제점
필자의 데이터베이스는 MySQL를 사용하고 있습니다.
MySQL의 AUTO_INCREMENT 옵션은 기본키를 연속적으로 생성해주는 옵션인데요.
일반적으로 JPA를 사용할 때 엔티티의 기본키 생성 전략을 GenerationType.IDENTITY로 가져갑니다.
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long authorId;
@Lob
private String contents;@Id(기본키)로 지정된 필드가 비어있는데 어떻게 영속화가 가능할까요?
Hibernates에서는 IDENTITY 전략을 사용할 경우 save 할 때 데이터베이스에 일단 INSERT 한 뒤 생성된 기본키를 가져옵니다.
그러다 보니 Bulk Insert 할 때 N번 째 데이터의 기본키(식별자)를 채번 하기 위해 N-1 데이터까지 INSERT가 되어있는 상태에서 N번 째 데이터를 INSERT 하고 생성된 기본키를 가져오게 되어서 실질적으로 N번의 삽입 쿼리가 발생합니다.
ValdMihalcea의 How do persist and merge work in JPA를 참고하면 위와 같은 채번 원리 때문에 Hibernates에서는 기본적으로 IDENTITY 기본키 생성 전략을 가져갈 때 Batch Insert를 허용하지 않는다는 것을 알 수 있습니다.
postRepository.saveAll(posts);Hibernate: insert into post (author_id, contents) values (?, ?)
Hibernate: insert into post (author_id, contents) values (?, ?)
Hibernate: insert into post (author_id, contents) values (?, ?)
Hibernate: insert into post (author_id, contents) values (?, ?)
Hibernate: insert into post (author_id, contents) values (?, ?)실제 spring.jpa.show-sql=true을 주고 쿼리를 확인해 본 결과 N번의 삽입 쿼리가 발생합니다.
이는 데이터베이스 성능 저하의 원인이 되고 결과적으로 서버 응답 시간이 길어지기 때문에 개선할 필요가 있어 보입니다.
총 2가지 대안
그렇다면 saveAll을 정상적으로 동작시키기 위한 방법은 없을까요?
아래에서 대표적인 대안 2가지를 소개하겠습니다.
(그 외 대안도 있지만 이 포스팅에서는 키워드 정도만 소개하겠습니다)
대안 1. 기본키 생성 전략 변경
GenerationType.SEQUENCE 또는 GenerationType.TABLE 방식을 사용하는 것입니다.
다만, MySQL은 SEQUENCE 채빈 방식을 지원하지 않기 때문에 TABLE 채번 방식을 활용해 보도록 하겠습니다.
(단 기본키 전략을 변경하게 되면 DB 스키마를 변경해야 됩니다.)
아래는 테이블 스키마입니다.
CREATE TABLE post
(
id BIGINT PRIMARY KEY,
contents TEXT NOT NULL,
author_id BIGINT NOT NULL
);
CREATE TABLE sequence
(
table_name VARCHAR(255) NOT NULL PRIMARY KEY ,
next_val BIGINT
);Entity 클래스의 코드를 다음과 같이 추가 / 변경합니다.
@TableGenerator(
name = "post_sequence_generator", // Generator 이름
table = "sequence", // TABLE 전략에 사용할 테이블명
pkColumnName = "table_name", // 생성 전략 테이블의 PK 컬럼명
pkColumnValue = "post", // 생성 전략 테이블의 PK 값
allocationSize = 10000 // 한 번에 가져올 SEQUENCE 크기 (1이면 한 번씩 쿼리 나갑니다)
)
public class Post {
@Id
@GeneratedValue(
strategy = GenerationType.TABLE, // 생성 전략 변경
generator = "post_sequence_generator" // 위에서 정의한 TableGenerator Name
)
private Long id;
private Long authorId;
@Lob
private String contents;기본에 Bulk Insert가 되지 않는 상태에서 saveAll의 시간대비 확연하게 줄어든 것을 확인할 수 있습니다.
단, spring.jpa.show-sql=true 옵션만 준 상태에서는 INSERT 쿼리가 여러 번 나간 것처럼 보입니다.
그럴 땐 spring.datasource.url 에 아래와 같은 옵션을 추가하면 INSERT 쿼리가 합쳐서 나가는 것을 확인할 수 있습니다.
?rewriteBatchedStatements=true&profileSQL=true&logger=Slf4JLogger&maxQuerySizeToLog=999999또 설정 파일에 다음과 같은 옵션을 넣어주고 Batch Size는 적절하게 조절하면 됩니다.
(자세한 내용들은 직접 찾아보길 권장합니다.)
spring:
jpa:
properties:
hibernate:
jdbc:
batch_size: 10000
batch_versioned_data: true
order_inserts: true
order_updates: true
실행 결과를 잘 살펴보면 아래와 같이 쿼리가 한 번에 나가는 것을 확인할 수 있습니다.
.
.
.
[QUERY] insert into post (author_id, contents, id) values (0, x'30', 21102),(1, x'31', 21103),(2, x'32', 21104),
(3, x'33', 21105),(4, x'34', 21106),(5, x'35', 21107)
이 방법엔 치명적인 단점들이 있습니다. 바로 별도의 테이블을 생성해서 관리해야 한다는 점과 기존 IDENTITY 전략을 TABLE 전략으로 변경한다는 점에서 설계가 변경되는 점입니다. 따라서 다른 대안이 필요합니다.
대안 2. JDBC batchUpdate
다행히도 별도의 테이블을 만들지 않고 기본키 생성 전략도 변경하지 않는 방법이 있습니다.
바로 Jdbc의 batchUpdate를 사용하는 방법입니다.
Spring Boot Data JPA 의존성을 추가하면 기본적으로 JDBC 의존성도 같이 추가되기 때문에 별도로 설정할 필요가 없어서 좋습니다.
DI를 통해서 JdbcTemplate를 주입받고 활용하면 됩니다.
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;@Repository
@RequiredArgsConstructor
public class PostCustomRepositoryImpl implements PostCustomRepository {
private final JdbcTemplate jdbcTemplate;
@Override
public List<Long> batchUpdate(List<Post> posts) {
return Arrays.stream(
jdbcTemplate.batchUpdate(
"INSERT INTO post (contents, author_id) VALUES (?, ?)",
new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setString(1, posts.get(i).getContents());
ps.setLong(2, posts.get(i).getAuthorId());
}
@Override
public int getBatchSize() { return posts.size(); }
}
))
.boxed()
.map(Integer::longValue)
.toList();
}
}그 외 설정 파일에 대안 1 (GenerationType.TABLE)에서 설정한 DataSource URL 옵션만 추가해 주면 됩니다.
JDBC Template과 batchUpdate에 대한 내용은 관련 자료를 더 찾아보면 될 것 같습니다.
그 외
- Mybatis <foreach>
- JOOQ
- QueryDSL-SQL
위 방법들을 사용하여 해결할 수도 있지만 이 포스팅에 전부 다루기는 어렵기 때문에 2부에서 다루도록 하겠습니다 :)
성능 비교
총 10000건에 대해서 Bulk Insert 할 때 소요되는 시간을 측정해 보았습니다.
기존 (GenerationType.IDENTITY & JPARepository.saveAll)

대안 1. GenerationType.TABLE

대안 2. JDBC batchUpdate

JDBC batchUpdate를 사용하는 방법이 간단하며 설계 변경이 필요하지 않다는 점에서 여러 장점이 많은 것 같습니다.
참고 자료
'개발 > Spring Framework' 카테고리의 다른 글
| [Spring] 서비스 코드를 테스트하기 어렵다면? (0) | 2023.06.19 |
|---|---|
| TestContainers가 Docker 감지 못 하는 문제 (Mac) (1) | 2023.01.05 |
| IoC(제어의 역전), DI(의존관계 주입), Container(컨테이너) (0) | 2022.06.05 |